Как развернуть AI-агента OpenClaw на облачном сервере с GPU
Хотите создать собственного ИИ-ассистента, который будет писать код, анализировать данные, управлять инфраструктурой или решать другие сложные задачи? OpenClaw — это гибкая платформа для построения автономных AI-агентов, поддерживающая любые модели: от публичных API до ваших приватных эндпоинтов с закрытыми LLM.
Арендуя облачный сервер с GPU в immers.cloud, вы получаете готовую среду для запуска OpenClaw — без возни с драйверами, зависимостями и настройкой железа. Это идеальное решение для тех, кто ищет сервер для разработки, но не хочет тратить время на настройку и поддержание инфраструктуры.
В нашем маркетплейсе образов уже доступен OpenClaw. Его настройка не требует жесткой технической экспертизы. Просто следуйте этой простой инструкции.
При создании виртуальной машины с образом OpenClaw на Ubuntu 24.04 в поле «Пользовательские данные» (user data) автоматически подставляется пресет конфигурации, включающий настройки для работы с моделью Qwen3-Coder-Next.
⚠️ Важно: сам образ не содержит предзаписанной конфигурации — она добавляется только при создании виртуальной машины через веб-интерфейс.
Если вы хотите использовать другую модель — отредактируйте конфигурационный файл после запуска, как описано ниже.
Запустите виртуальную машину с видеокартой
Перейдите в панель управления immers.cloud и создайте виртуальную машину:
- Выберите образ OpenClaw;
- Выберите подходящую конфигурацию (лучше всего подойдет CPU-сервер от двух ядер и 8 гб оперативной памяти);
- Настройте CPU, RAM и диск по желанию;
- Нажмите «Расширенные настройки» и вставьте в поле «Пользовательские данные» конфигурацию для связи OpenClaw с публичным LLM-эндпоинтом (см. ниже).
- Нажмите «Создать» — сервер будет готов через несколько минут.
Конфигурация для связи OpenClaw с публичным LLM-эндпоинтом (на примере Qwen3-Coder-Next):
Примечание: В настоящий момент среди публичных эндпоинтов только эндпоинт Qwen3-Coder-Next поддерживает OpenClaw
Весь текст ниже необходимо скопировать без изменений в поле «Пользовательские данные»:
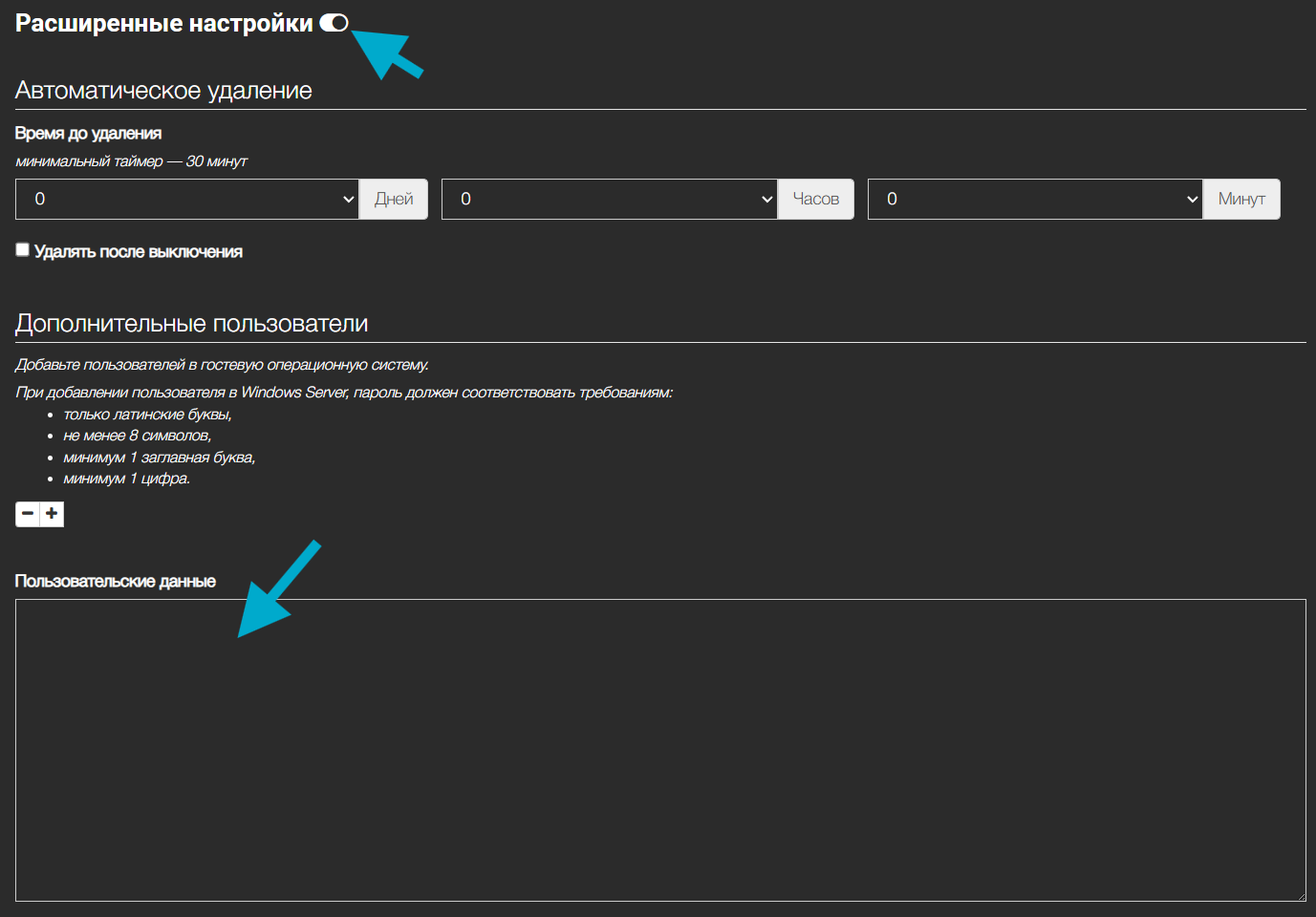
## template: jinja
#!/bin/bash
OPENAI_ENDPOINT="https://chat.immers.cloud/v1/endpoints/qwen3-coder-test/generate/"
OPENAI_API_KEY="Ваш Токен"
MODEL_ID="Qwen3-Coder-Next"
MODEL_NAME="Qwen3-Coder-Next"
MODEL_CONTEXT="262144"
cat > /home/ubuntu/.immersopenclaw/customdata <<EOF
{
"models": {
"mode": "merge",
"providers": {
"${MODEL_NAME}": {
"baseUrl": "${OPENAI_ENDPOINT}",
"apiKey": "${OPENAI_API_KEY}",
"api": "openai-completions",
"models": [
{
"id": "${MODEL_ID}",
"name": "${MODEL_NAME}",
"reasoning": true,
"input": ["text"],
"cost": {"input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0},
"contextWindow": ${MODEL_CONTEXT}
}
]
}
}
},
"agents": {
"defaults": {
"compaction": {
"mode": "safeguard"
},
"maxConcurrent": 4,
"model": {
"primary": "qwen3-coder-test/${MODEL_ID}"
},
"subagents": {
"maxConcurrent": 8
},
"workspace": "/home/ubuntu/.openclaw/workspace"
}
}
}
EOF
echo "Successfully done!"
OPENAI_ENDPOINT = "https://chat.immers.cloud/v1/endpoints/qwen3-coder-test/generate/" — Это выбор эндпоинта
OPENAI_API_KEY = "Ваш Токен" — Выбор токена OpenAI, который вы получаете на странице управления токенами
MODEL_ID — ID модели
MODEL_NAME — Имя модели
MODEL_CONTEXT — Размер контекстного окна модели
Этот образ уже включает OpenClaw 2026.2.6-3 и NGINX 1.24.0 (настроен как reverse proxy), так что дополнительная установка не требуется.
Как только сервер запустится, дождитесь появления ссылки OpenClaw в разделе «Адреса» на странице вашей ВМ. По ней вы попадете в веб-интерфейс OpenClaw Control.
Опционально: Подключите свою ИИ-модель
Для подключения своей модели перед созданием сервера отредактируйте пользовательские данные, которые указаны выше в Настройке публичного эндпоинта LLM
и укажите в соответствующих полях:
OPENAI_ENDPOINT= "https://chat.immers.cloud/v1/endpoints/qwen3-coder-test/generate/" — Это выбор эндпоинтаOPENAI_API_KEY= "Ваш Токен" — Выбор токена OpenAI, который вы получаете на сайтеMODEL_ID— ID моделиMODEL_NAME— Имя моделиMODEL_CONTEXT— Размер контекстного окна модели
Вы так же можете указать свои дополнительные параметры в секции конфигурации, что бы применить их к вашему файлу конфигурации при старте сервера.
Сохраните файл и перезапустите OpenClaw (если потребуется).
Готово! Теперь ваш ИИ-агент может использовать мощности GPU для выполнения задач с высокой скоростью и точностью.
Преимущества такого подхода:
- Полная приватность: модель работает через ваш приватный эндпоинт, данные не покидают облако;
- Масштабируемость: при росте нагрузки можно легко перейти на сервер с двумя или восемью GPU;
- Экономия времени: не нужно собирать серверную платформу с GPU вручную — всё уже настроено;
- Гибкость: можно подключать любые модели — даже те, что работают в формате Completions, что особенно важно для open-source экосистемы.
Почему стоит выбрать аренду облачного сервера с GPU в immers.cloud?
- Доступ к серверам с мощными видеокартами NVIDIA (RTX 4090, A100, H100, H200 и др.);
- Предустановленные образы для самых разных задач;
- Посекундная тарификация — платите только за время работы сервера
- Полный контроль над данными — никакой передачи кода во внешние облака
- Поддержка виртуальных машин с видеокартой и оригинального OpenStack API
Это делает immers.cloud одной из лучших облачных платформ с GPU в России для разработчиков, исследователей и компаний, работающих с ИИ.