Публичные и частные эндпоинты — полное руководство
Добро пожаловать в современный сервис для работы с моделями искусственного интеллекта! Мы собрали обширный каталог решений. Основу составляют наиболее востребованные большие языковые модели (large language models, LLM), используемые во множестве задач генерации и анализа текстов, в том числе маркетинговых материалов, юридических документов, бизнесс стратегий или кода разных языков программирования. Также в каталоге представлены модели генерации изображений, видео и аудио.
Здесь вы найдёте модели разного масштаба и специализации: универсальных или узкопрофильных "помощников", заточенных под конкретные задачи. Чтобы оценить и выбрать, то что подходит именно Вам воспользуйтесь возможностью быстро запустить инференс прямо в интерфейсе платформы: протестируйте модель на своих данных, сравните результаты и выберите оптимальное решение без сложной настройки инфраструктуры.
Мы стремимся сделать технологии ИИ доступными — будь вы разработчик, исследователь или бизнес-пользователь. В этом гайде мы подробно расскажем, как запустить публичные и приватные эндпоинты.
Как устроен каталог моделей: обзор возможностей
Страница каталога предоставляет пользователям структурированный перечень доступных моделей. Каждая позиция в списке включает:
- Краткое описание модели, раскрывающее её основные возможности и типичные сценарии применения;
- Набор тегов, отражающих ключевые характеристики (тип задачи, модальность, специализация), в том числе специальный тэг «Можно попробовать» (указывает на возможность бесплатно попробовать модель в рамках публичных эндпоинтов).

Для работы с списком доступно окно поиска, позволяющее фильтровать список по названию моделей, и механизм сортировки, который даёт возможность упорядочивать результаты по различным критериям (по количеству параметров, контексту, дате публикации и возможности попробовать модель в рамках публичных эндпоинтов).
Такая организация каталога обеспечивает быстрый и точный подбор модели в соответствии с требованиями конкретного проекта. Из каталога можно перейти на страницу модели с URL: вида https://immers.cloud/ai/<производитель>/<название модели>/ (например, https://immers.cloud/ai/google/gemma-4-26b-a4b-it/), которая позволяет работать с набором сервисов в рамках платформы immers.cloud:
- Сервис публичных эндпоинтов;
- Сервис подбора рекомендуемых конфигураций серверов;
- Сервис частных эндпоинтов.
Подобрать модель под конкретную задачу бывает непросто — разные требования, ресурсы и возможности требуют своих подходов. Именно поэтому в рамках платформы можно как бесплатно попробовать инференс в рамках Сервиса публичных эндпоинтов, так и обеспечить индивидуальные функциональные требования в рамках частных серверов или эндпоинтов.
Сервис публичных эндпоинтов
Использование публичных энпдоинтов доступно всем авторизованным пользователям. Мы следим за выходом открытых open source AI-моделей и оперативно предоставляем к ним доступ. Чтобы быстро попробовать модель достаточно открыть интерфейс чата - для этого на странице модели необходимо перейти по ссылке «Чат» в пункте «Публичный эндпоинт».
Чтобы попробовать модель в рамках своего рабочего инструмента или во время разработки своего программного обеспечения можно использовать API. Примеры запросов приведены на странице модели. Для доступа необходимо создать токен. Для этого необходимо перейти на страницу управления токенами.
Используя данный публичный сервис, вы подтверждаете, что полностью ознакомились с Условиями использования сервиса «Публичные эндпоинты» и принимаете их в полном объеме без каких-либо оговорок и исключений.
Сервис подбора рекомендуемых конфигураций серверов
Серьезные приложения требуют стабильный доступ к нужной функциональности с гарантированным уровнем качества. Если сервис «Публичные эндпоинты» не покрывает всех Ваших нужд, то Вы можете воспользоваться нашими рекомендациями для создания частного сервера, где Вы сможете организовать работу так, как требуется именно Вам. Доступна аренда с почасовой оплатой или на длительный срок с помесячной оплатой. Подробнее см. в FAQ.
Подбор подходящего варианта сервера является сложной задачей, требующей высокой квалификации в предметной области. Он должен основываться на характеристиках самой модели (архитектура, количество параметров и пр.), характеристиках инференса (длина контекста, параллельность и пр.) и характеристиках конфигурации сервера. Мы предлагаем широкий ряд конфигураций, включащий варианты с GPU, на основе которых и строится инференс больших нейронных сетей. Чтобы облегчить Ваш выбор мы сами составляем рекомендации для каждой модели.
В последние годы наблюдается тенденция: чем больше параметров в ИИ-модели, тем выше её качество. Однако крупные модели требуют дорогостоящих серверов с мощными GPU, что создаёт значительную нагрузку на бюджет.
Для оптимизации затрат применяют квантование — снижение точности представления весов и активаций модели с стандартных 32 bit (FP32) до меньших форматов. Чаще всего используют
- 4 bit (максимальная экономия ресурсов, возможны потери в качестве);
- 8 bit (оптимальный баланс между размером модели и качеством);
- 16 bit (минимальное снижение точности, почти без потерь качества).
Таким образом, квантование помогает снизить затраты на инфраструктуру и использовать мощные ИИ-модели даже при ограниченном бюджете.
Именно поэтому мы готовим рекомендации сразу для каждой битности. Чтобы воспользоваться рекомендациями достаточно перейти на страницу модели и пролистать до пункта «Рекомендуемые конфигурации сервера для хостинга». В зависимости от типа модели доступно два варианта использования:
- Если модель относится к LLM или visual LLM, то по нажатию на кнопку «Запустить» откроется страница создания частного эндпоинта. Подробнее про сервис частных эндпоинтов будет написано ниже. Если Вы хотите самостоятельно разверунть модель с помощью своих инструментов, то Вы можете создать сервер с выбранной конфигурацией в рамках базового функционала платформы по аренде серверов;
- Для остальных моделей (генерации изображений, видео, аудио) доступно создание сервера по нажатию на кнопку «Запустить».
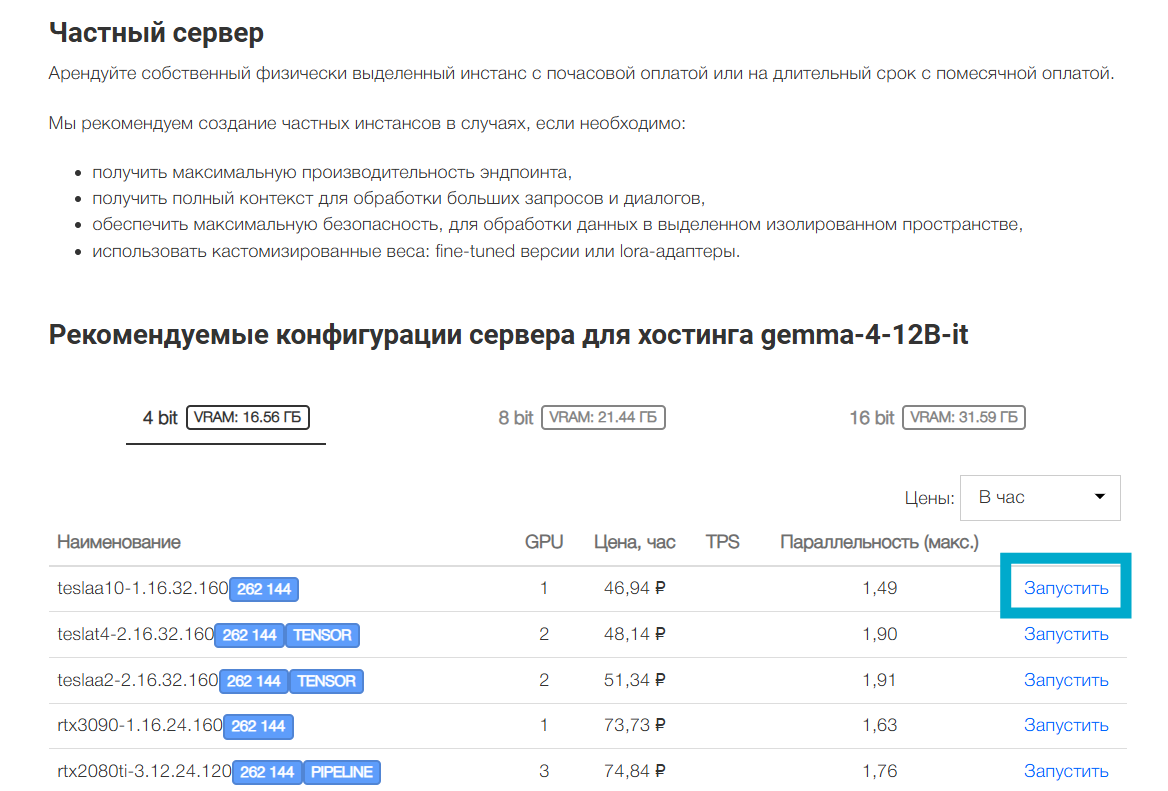
Из-за высокого спроса не все конфигурации доступны постоянно. Вы можете нажать на иконку «колокольчик» и подписаться на уведомление о доступности. Как только указанное количество конфигураций снова будет доступно для аренды Вам будет отправлено уведомление.
Сервис частных эндпоинтов
К современному инференсу предъявляются строгие требования: высокая надёжность, поддержка пакетной обработки, эффективное использование видеопамяти и удобный API — желательно в формате OpenAI API, чтобы упростить интеграцию. vLLM идеально соответствует всем этим параметрам: демонстрирует стабильную производительность, реализует непрерывную пакетную обработку запросов, оптимизирует потребление VRAM
и предоставляет удобный разработчикам интерфейс.
Именно поэтому мы остановили выбор на этом движке в качестве бэкенда для нашего сервиса — он гарантирует качество и удобство на всех этапах работы.
Идеология нашего сервиса заключается в предоставлении возможности тестировать различные варианты запуска инференса для поиска оптимальной комбинации конфигурации и параметров под конкретные задачи. Поэтому мы создали сервис как удобную playground-площадку для запуска vLLM — чтобы вы могли легко экспериментировать и выбирать наилучшие настройки.
Создание частного эндпоинта
Создание частных эндпоинтов доступно для авторизованных пользователей. Для создания необходимо:
- Перейти из каталога на страницу интересующей Вас модели. На странице каталога доступен поиск по названию;
- Прокрутить страницу до пункта «Рекомендуемые конфигурации сервера для хостинга». В таблице приведены конфигурации, на которых инференс весов выбранной битности предположительно запустится с помощью vLLM. Также указаны количество GPU в конфигурации, цена аренды конфигурации и расчетные значения статистики инференса TPS («tokens per second» равен количеству токенов, генерируемых моделью за секунду) и параллельности (максимальное количество одновременных запросов с полным контекстом, которые сможет обработать эндпоинт);
- Нажать на кнопку «Запустить» в строке выбранной конфигурации;
- На открывашейся странице с формой создания эндпоинта указать все необходимые и если нужно расширенные настройки.
Обязательные настройки
| Настройка | Описание |
|---|---|
| Веса |
Выбор из добавленных в каталог моделей с Hugging Face. Из-за спроса на более дешевый инференс производители выпускают не только модели в том типе данных, в котором производилась тренировка, но и в квантованных вариантах. Также в выборке могут встречаться варианты квантованных весов других производителей. |
| Контекст |
Длина контекста — это максимальный объём текстовой информации в токенах, который большая языковая модель (LLM) способна учитывать при формировании ответа. По умолчанию проставлено максимальное значение, с которым модель может работать. Во время генерации ответа видеопамять тратится на промежуточные вычисления, объем которых зависит от указанной длины контекста. Таким образом, с меньшей длиной контекста можно поднять модель на более дешевой конфигурации с меньшим суммарным количеством видеопамяти. Оценить необходимую длину контекста можно исходя из Вашей задачи:
Важно: Реальная эффективная длина контекста может отличаться от заявленной из-за накладных расходов на промпт, системные сообщения и ограничения инфраструктуры. Всегда тестируйте модель на реальных данных перед внедрением. |
| Сеть |
Платформа поддерживает развёртывание эндпоинтов как во внешней, так и в частной сети. Для быстрого запуска без трудоёмкой настройки оптимальным решением станет создание эндпоинта во внешней сети. Чтобы приступить к работе, достаточно выбрать подходящего провайдера из предложенного списка и ваш эндпоинт будет готов к использованию. При работе с корпоративными документами безопасность данных выступает критическим требованием: утечка или несанкционированный доступ могут привести к серьёзным последствиям. Частная сеть даёт возможность самостоятельно настроить уровни доступности, контроля и защиты данных согласно внутренним политикам компании. Для ограничения доступа к ресурсам целесообразно развернуть эндпоинт в пределах частной сети: это обеспечит изоляцию сервиса и снизит риски внешних воздействий. Создать частную сеть необходимо перед созданием частного эндпоинта. |
| Конфигурация |
Выбор конфигурации является критическим при создании эндпоинта (подробнее см. в пункте «Сервис подбора рекомендуемых конфигураций серверов»). Обращаем Ваше внимание, что при смене контекста и весов набор рекомендуемых конфигураций будет обновляться. При выборе конфигурации рекомендуем обратить внимание на валидированные - они отмечены кружками:
|
| Количество инстансов |
Объём запросов к эндпоинту варьируется: от умеренного в небольших проектах до интенсивного в продакшн среде. Эндпоинт справится с любой нагрузкой: под капотом он может объединять несколько серверов, равномерно распределяя запросы между ними через балансировщик. Вы можете масштабировать эндпоинт, указав нужное количество серверов, на которых нужно развернуть инференс, — это обеспечит стабильную работу при любой нагрузке. |
| Ключевая пара | Для подключения к серверу потребуется ключевая пара. Создайте её автоматически (выберите «Создать новую Ключевую Пару») или на основе собственного публичного ключа для большей безопасности.. |
Расширенные (необязательные) настройки
| Настройка | Описание |
|---|---|
| Log Level | Уровень логирования. Возможные значения - DEBUG, INFO. |
| Версия vLLM |
Проект vLLM активно развивается - постоянно выкладываются обновления с поддержкой недавно вышедших open source моделей. Это открытый проект и из-за большого объема работы не все версии стабильны и для определенных моделей бывает необходимым указывать конкретную версию Docker-образа. |
| GPU_MEMORY_ UTILIZATION |
Во фреймворке vLLM параметр По умолчанию он установлен на 0,92 (92 %).
В таких случаях рекомендуется снизить |
| max_num_batche d_tokens |
Параметр Это ограничение влияет на размер батча по количеству токенов, балансируя пропускную способность и использование памяти GPU. Настройка этого параметра позволяет оптимизировать производительность модели под конкретные требования: снижение задержки, увеличение пропускной способности или балансировка использования памяти. |
| max_num_seqs |
Параметр Это позволяет поддерживать высокую загрузку GPU. |
| Tooling |
В vLLM tooling относится к поддержке вызова инструментов (tool calling) — функции, которая позволяет языковой модели использовать внешние инструменты или функции для выполнения задач, выходящих за рамки её базового функционала. Это особенно полезно для сценариев, где модель нуждается в помощи для решения сложных задач, требующих доступа к внешним ресурсам или выполнения определённых действий. |
| Tooling Parser | Параметр позволяет выбрать парсер для обработки вызовов инструментов (tool calling). |
Нажмите на кнопку «Создать». По нажатию кнопки откроется страница эндпоинта, где указаны все его характеристики.
Процесс создания эндпоинта требует определённого времени — от 10 минут до 1 часа. В ходе развёртывания:
- Будут созданы сервера в соответствии с указанным количеством инстансов. Список можно посмотреть в разделе «Мое облако»;
- Настроены сетевые параметры и группы безопасности;
- На каждом сервере будет развернута среда для выполнения инференса и будет запущен vLLM, который автоматически скачает необходимые файлы модели .
Если создание завершится с ошибками, то статус у эндпоинта будет равен Unavailable. Подробнее см. в пункте «Диагностика проблем».
Проверка работоспособности частного эндпоинта
Для быстрой проверки Вы можете воспользоваться интерфейсом чата. Для этого нажмите на ссылку Чат рядом с значением поля «Статус».
vLLM предоставляет API, совместимый с OpenAI. Это удобно, поскольку позволяет интегрировать фреймворк в существующие решения без доработки клиентского кода — достаточно перенаправить запросы на новый эндпоинт и указать токен. Создание токена доступно на странице управления токенами. Чтобы проверить работоспособность созданного эндпоинта, воспользуйтесь следующими примерами запросов:
cURL
curl <значение поля URL на странице эндпоинта>/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <Ваш токен>" \
-d '{"model": "<значение поля модель на странице эндпоинта>",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Say this is a test"}
], "temperature": 0, "max_tokens": 150}'
PowerShell
$response = Invoke-WebRequest <значение поля URL на странице
эндпоинта>/chat/completions `
-Method POST `
-Headers @{
"Authorization" = "Bearer <Ваш токен>"
"Content-Type" = "application/json"
} `
-Body (@{
model = "<значение поля модель на странице эндпоинта>"
messages = @(
@{ role = "system"; content = "You are a helpful assistant." },
@{ role = "user"; content = "Say this is a test" }
)
} | ConvertTo-Json)
($response.Content | ConvertFrom-Json).choices[0].message.content
Python
from openai import OpenAI
client = OpenAI(
api_key="<Ваш токен>",
base_url="<значение поля URL на странице эндпоинта>",
)
chat_response = client.chat.completions.create(
model="<значение поля модель на странице эндпоинта>",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Say this is a test"},
]
)
print(chat_response.choices[0].message.content)
Диагностика проблем
Наша платформа построена на идеологии предоставления playground-площадки для запуска vLLM. Мы обеспечиваем высокую гибкость настройки эндпоинтов: Вы можете адаптировать параметры под конкретные требования Вашей задачи. При этом важно учитывать, что не каждый сценарий запуска vLLM гарантирует эффективность и стабильный инференс из-за особенностей нагрузки, модели или ресурсов.
Если при развёртывании эндпоинта вы столкнулись с проблемой, обратитесь к нашим рекомендациям по диагностике и устранению ошибок — в них описаны типичные ситуации и способы их решения.
Эндпоинт находится в статусе Unavailable. Во время создания и разворачивания эндпоинта произошла ошибка. В этом случае удалите этот эндпоинт и создайте новый с измененными параметрами. Рекомендуем обратить внимание на проверенные конфигурации - они отмечены зеленым кружком в списке конфигураций;
Эндпоинт перестал отвечать после некоторого времени стабильной работы. Эндпоинт успешно развернулся и ранее Вы проверили его работоспособность, но на данный момент эндпоинт не отвечает. Есть несколько возможных причин такого поведения:
- Под капотом эндпоинта работает сервер, за аренду которого снимается оплата. В случае нулевого баланса сервер будет остановлен и отправлен в архив (Shelve). В этом случае удалите этот эндпоинт, пополните баланс и создайте новый;
- Произошла критическая ошибка в работе VLLM — слишком большое количество одновременных запросов, нехватка видеопамяти CUDA (ошибка
Out of Memory) или внутренняя ошибка в работе фреймворка VLLM. В этом случае удалите этот эндпоинт и создайте новый с измененными параметрами. - Запросы падают с ошибкой «404: No Endpoint matches the given query». Эндпоинт не доступен. Если эндпоинт находится в статусе
Unavailable, то см. соответствующий пункт выше. Если эндпоинт ранее работал стабильно, но на данный момент не отвечает, то см. соответствующий пункт выше.
Если Вы не нашли способ решения возникшей проблемы или есть еще вопросы по работе сервиса — cвяжитесь с нашей специализированной группой поддержки по нейросетям nn@immers.cloud или обратитесь в службу технической поддержки (Max, Telegram).
Важно! Рекомендуем не удалять эндпоинт до обращения в службу технической поддержки, т.к. для выявляения проблемы потребуются логи cо связанных с эндпоинтом серверов, которые удалятся после удаления эндпоинта и связанных серверов.
Удаление частного эндпоинта
Удаление частных эндпоинтов доступно для авторизованных пользователей. Для удаления необходимо перейти на страницу ендпоинта и нажать на кнопку «Удалить». После этого начнется процесс удаления эндпоинта: будут удалены связанные серверы и группы безопасности.